
This article is part of our reviews of AI research papers, a series of posts that explore the latest findings in artificial intelligence.
The human hand is one of the fascinating creations of nature, and one of the highly sought goals of artificial intelligence and robotics researchers. A robotic hand that could manipulate objects as we do would be enormously useful in factories, warehouses, offices, and homes.
Yet despite tremendous progress in the field, research on robotics hands remains extremely expensive and limited to a few very wealthy companies and research labs.
Now, new research promises to make robotics research available to resource-constrained organizations. In a paper published on arXiv, researchers at the University of Toronto, Nvidia, and other organizations have presented a new system that leverages highly efficient deep reinforcement learning techniques and optimized simulated environments to train robotic hands at a fraction of the costs it would normally take.
Training robotic hands is expensive
{kind=link}
For all we know, the technology to create human-like robots is not here yet. However, given enough resources and time, you can make significant progress on specific tasks such as manipulating objects with a robotic hand.
In 2019, OpenAI presented Dactyl, a robotic hand that could manipulate a Rubik’s cube with impressive dexterity (though still significantly inferior to human dexterity). But it took 13,000 years’ worth of training to get it to the point where it could handle objects reliably.
How do you fit 13,000 years of training into a short period of time? Fortunately, many software tasks can be parallelized. You can train multiple reinforcement learning agents concurrently and merge their learned parameters. Parallelization can help to reduce the time it takes to train the AI that controls the robotic hand.
However, speed comes at a cost. One solution is to create thousands of physical robotic hands and train them simultaneously, a path that would be financially prohibitive even for the wealthiest tech companies. Another solution is to use a simulated environment. With simulated environments, researchers can train hundreds of AI agents at the same time, and then finetune the model on a real physical robot. The combination of simulation and physical training has become the norm in robotics, autonomous driving, and other areas of research that require interactions with the real world.
Simulations have their own challenges, however, and the computational costs can still be too much for smaller firms.
OpenAI, which has the financial backing of some of the wealthiest companies and investors, developed Dactyl using expensive robotic hands and an even more expensive compute cluster comprising around 30,000 CPU cores.
Lowering the costs of robotics research

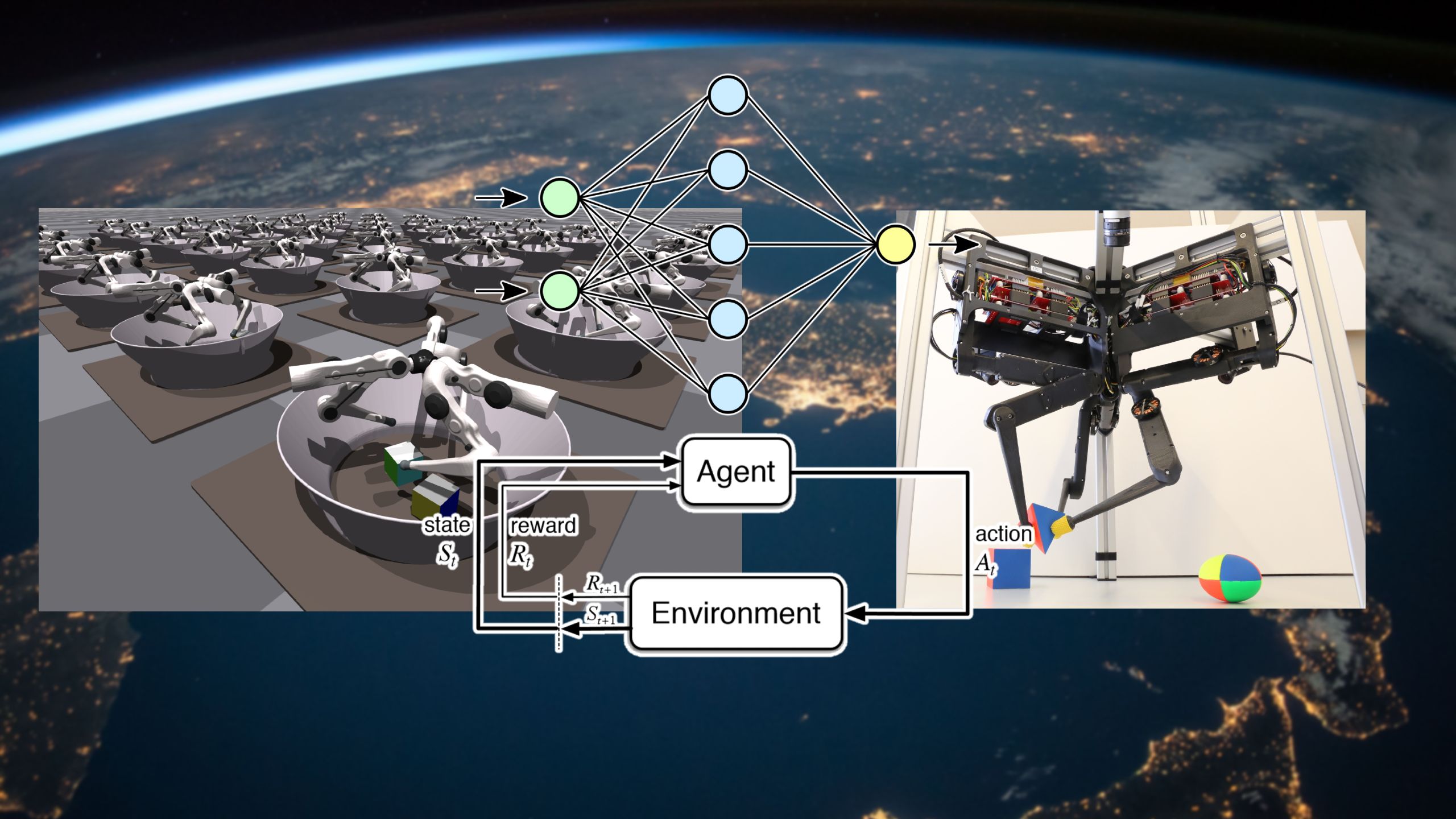
In 2020, a group of researchers at the Max Planck Institute for Intelligent Systems and New York University proposed an open-source robotic research platform that was dynamic and used affordable hardware. Named TriFinger, the system used the PyBullet physics engine for simulated learning and a low-cost robotic hand with three fingers and six degrees of freedom (6DoF). The researchers later launched the Real Robot Challenge (RRC), a Europe-based platform that gave researchers remote access to physical robots to test their reinforcement learning models on.
The TriFinger platform reduced the costs of robotic research but still had several challenges. PyBullet, which is a CPU-based environment, is noisy and slow and makes it hard to train reinforcement learning models efficiently. Poor simulated learning creates complications and widens the “sim2real gap,” the performance drop that the trained RL model suffers from when transferred to a physical robot. Consequently, robotics researchers need to go through multiple cycles of switching between simulated training and physical testing to tune their RL models.
“Previous work on in-hand manipulation required large clusters of CPUs to run on. Furthermore, the engineering effort required to scale reinforcement learning methods has been prohibitive for most research teams,” Arthur Allshire, lead author of the paper and a Simulation and Robotics Intern at Nvidia, told TechTalks. “This meant that despite progress in scaling deep RL, further algorithmic or systems progress has been difficult. And the hardware cost and maintenance time associated with systems such as the Shadow Hand [used in OpenAI Dactyl] … has limited the accessibility of hardware to test learning algorithms on.”
Building on top of the work of the TriFinger team, this new group of researchers aimed to improve the quality of simulated learning while keeping the costs low.
Training RL agents with single-GPU simulation
{kind=link}
The researchers replaced the PyBullet with Nvidia’s Isaac Gym, a simulated environment that can run efficiently on desktop-grade GPUs. Isaac Gym leverages Nvidia’s PhysX GPU-accelerated engine to allow thousands of parallel simulations on a single GPU. It can provide around 100,000 samples per second on an RTX 3090 GPU.
“Our task is suitable for resource-constrained research labs. Our method took one day to train on a single desktop-level GPU and CPU. Every academic lab working in machine learning has access to this level of resources,” Allshire said.
According to the paper, an entire setup to run the system, including training, inference, and physical robot hardware, can be purchased for less than $10,000.
The efficiency of the GPU-powered virtual environment enabled the researchers to train their reinforcement learning models in a high-fidelity simulation without reducing the speed of the training process. Higher fidelity makes the training environment more realistic, reducing the sim2real gap and the need for finetuning the model with physical robots.
The researchers used a sample object manipulation task to test their reinforcement learning system. As input, the RL model receives proprioceptive data from the simulated robot along with eight keypoints that represent the pose of the target object in three-dimensional Euclidean space. The model’s output is the torques that are applied to the motors of the robot’s nine joints.
The system uses the Proximal Policy Optimization (PPO), a model-free RL algorithm. Model-free algorithms obviate the need to compute all the details of the environment, which is computationally very expensive, especially when you’re dealing with the physical world. AI researchers often seek cost-efficient, model-free solutions to their reinforcement learning problems.
The researchers designed the reward of robotic hand RL as a balance between the fingers’ distance from the object, the object’s destination location, and the intended pose.
To further improve the model’s robustness, the researchers added random noise to different elements of the environment during training.
Testing on real robots
Once the reinforcement learning system was trained in the simulated environment, the researchers tested it in the real world through remote access to the TriFinger robots provided by the Real Robot Challenge. They replaced the proprioceptive and image input of the simulator with the sensor and camera information provided by the remote robot lab.
The trained system transferred its abilities to the real robot a seven-percent drop in accuracy, an impressive sim2real gap improvement in comparison to previous methods.
The keypoint-based object tracking was especially useful in ensuring that the robot’s object-handling capabilities generalized across different scales, poses, conditions, and objects.
“One limitation of our method—deploying on a cluster we did not have direct physical access to—was the difficulty in trying other objects. However, we were able to try other objects in simulation and our policies proved relatively robust with zero-shot transfer performance from the cube,” Allshire said.
The researchers say that the same technique can work on robotic hands with more degrees of freedom. They did not have the physical robot to measure the sim2real gap, but the Isaac Gym simulator also includes complex robotic hands such as the Shadow Hand used in Dactyl.
This system can be integrated with other reinforcement learning systems that address other aspects of robotics, such as navigation and pathfinding, to form a more complete solution to train mobile robots. “For example, you could have our method controlling the low-level control of a gripper while higher level planners or even learning-based algorithms are able to operate at a higher level of abstraction,” Allshire said.
The researchers believe that their work presents “a path for democratization of robot learning and a viable solution through large scale simulation and robotics-as-a-service.”
You must be logged in to post a comment.